
Webアプリの更新
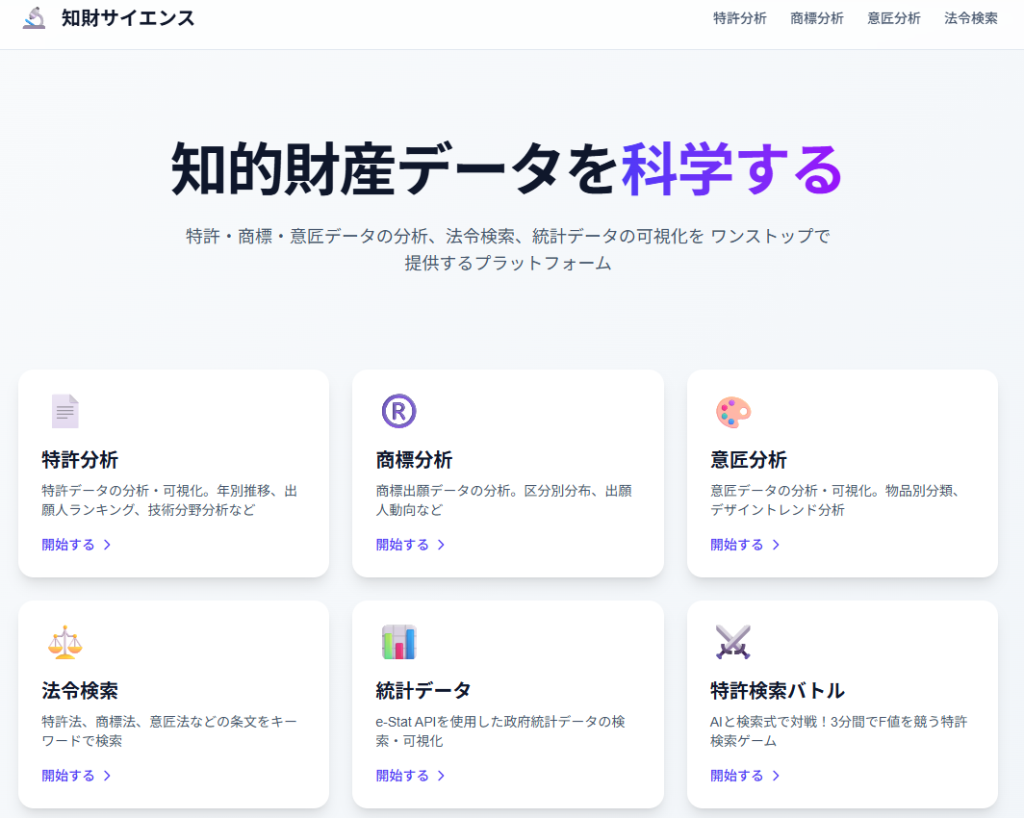
現在公開中のStreamlitのアプリを上記のようなモダンなアプリに変更中です。注目は右下にある特許検索バトルですね笑。
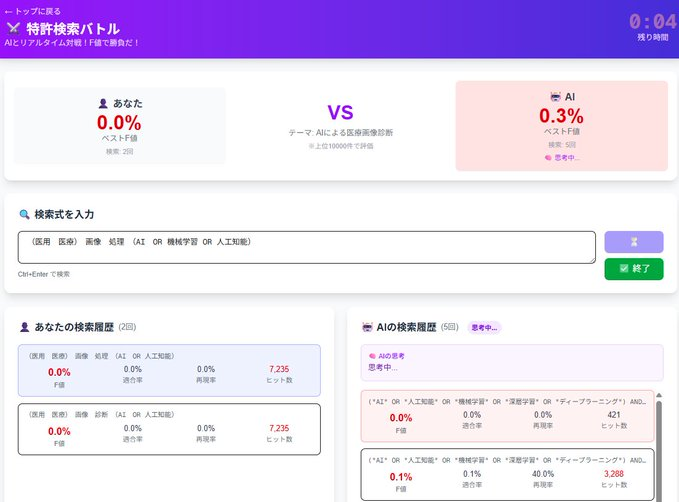
こんな感じでリアルタイムでバトルすることが出来ます。なかなか手強くてまだ勝ったことがないです。
IPC分類にも対応中です。
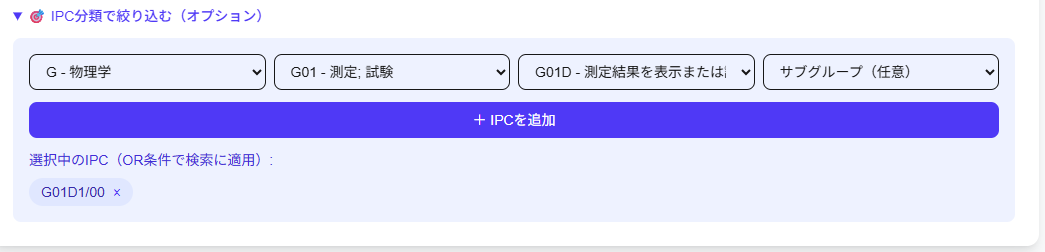
こんな感じでIPCをプルダウンで選択して入力する形式を考えています。複数のIPCは入力可能です。
現在公開中のStreamlitのアプリを上記のようなモダンなアプリに変更中です。注目は右下にある特許検索バトルですね笑。
こんな感じでリアルタイムでバトルすることが出来ます。なかなか手強くてまだ勝ったことがないです。
IPC分類にも対応中です。
こんな感じでIPCをプルダウンで選択して入力する形式を考えています。複数のIPCは入力可能です。
HPがようやくググって出てくるようになりました。設定がググっても検索出来ないようになっていたのに、私が気づいていなかったからです。
少しやる気が出てきたので、HPを少しづつ更新していこうと思います。
WebアプリはStreamlitで簡単なアプリを作っていましたが、もっと本格的なアプリに移行する予定です。
研究用途で実験的に作成しているので、実務に役立つか分からないような分析を載せていこうと考えています。
ただ、論文投稿していない内容は公開出来ないので、しばらくはあまり斬新な分析は載せられないと思いますが、Webアプリのツールとして高度な機能を試したいと考えています。
表題の「線形代数の半歩先」という本を購入しました。普段なら生成AIに質問しながら読み進めるところですが、その必要がないほど、非常に丁寧に書かれています。
生成AI時代には数学が大事だと考えているのですが、これはR&D部門にいたときの経験に関係します。
R&D部門にいたときに、世界的に有名な研究者と論文を読む機会がありました。
その研究者の論文の読み方は「数式を読む」というものでした。極論すれば「数式しか読まない」というものでした。
数式こそが技術であり、その説明文は数式の補足説明に過ぎず、全ては数式に書かれているというのです。
生成AIは自然言語で出力を出しますが、ひょっとしたら専門家にとっては冗長なのかもしれません。
少なくとも専門的な研究開発の分野では、数式で出力されるのが一般的になるかもしれません。数式で出力されても理解できるように、今から準備をしたいと思います。
先日の東京大学の記事に刺激を受けて、自分も生成AIを用いて何か新しい学問を身につけたいと思うようになりました。
独学で学ぶときにハルシネーションが起こっているかどうかの判断が難しそうな人文系ではなく、数学的に説明されたものが良さそうだと思いました。
そこで、統計検定2級は合格済みなので、統計検定準1級を受けようと思います。テキストは上記の2つが良さそうです。
これらの本は解説が付いていますが、独学では行間が広くて厳しいので、生成AIの助けを借りて進めようと思います。
答えがあるものであれば、ハルシネーションが行っているかどうかの判断がしやすいので、理数系の専門書や教科書が良さそうです。
東京大学のHPで、「AIを引っ提げてやってきた大学院生」という衝撃的な記事を見つけました。 記事によれば、経済学をほとんど学んだことがない学生が、生成AIを活用して1年かけて研究を行い、その成果について経済学者に意見を求めたとのことです。
経済学研究科の小川光教授がその研究を評価したところ、専門誌に挑戦できるほどの高い水準にあったそうです。
教授が驚いたのは、その学生が経済学の専門教育を一切受けておらず、研究のアイデア出しから、先行研究のレビュー、データ分析、英語での論文化まで、ほぼすべてをAIツールとの対話と独学で1年間かけて行っていたという点です。
教授自身もAIを研究に利用しているそうですが、専門外の分野でAIの力を借りて高いレベルのアウトプットを出すAIネイティブの登場に、恐怖さえ感じたと率直に綴っています。
さらに興味深いのは、学生が教授に意見を求めた理由です。AIは彼の研究を「国際誌に通用する水準」と評価したものの、彼自身には経済学の素養がないため、その評価が正しいのかわからないと感じたからでした。
これからも素人が国際誌に通用する水準で異分野に挑む人が増えてくると思います。自分の専門分野の効率化にだけ生成AIを用いるのは勿体ないのではないでしょうか。
大学での研究のベースとなりそうなLDA(Latent Dirichlet Allocation)の論文を読み始めました。
LDAは、文書が生成されるプロセスとして以下の2つの確率分布を仮定しています。
LDAは、観測されている「文書」と「単語」の情報から、これらの背後にある「トピックごとの単語分布」と「文書ごとのトピック分布」を同時に推定します。これにより、文書がどのようなトピックで構成されているかを分析するというものです。
大雑把にはこのように理解したのですが、論文中の数式を理解して、数学的な意味から理解できるように読み込んでいきたいと思います。
LDA(Latent Dirichlet Allocation)の論文を読む 続きを読む »
株式会社イーパテントが知財情報フェアで主催した「生成AI vs 人間」という企画で第1回の出題を担当しました。
先日、Perplexity Patentsで特許情報が検索可能になったので、「生成AI vs 人間」で私が担当した第1回の問題を解いてみました。
問題文はそのまま貼って、出力の形式だけを限定しました(私の出題では、日本の登録特許だけを正解にしたので、日本の登録特許を出力するように指示しました)。
Perplexity Patentsに入力したプロンプトは以下の通りです。
甲社の開発部門では、厚底ランニングシューズの人気を受け、日本国内での販売を目標に独自開発を進めていた。今般、厚底ランニングシューズに特有の「ミッドソールに配置されたプレートが、つま先からかかとに至る長手方向に湾曲する」という技術について、先行技術調査(特許調査)を行うこととなった。
採点対象となる技術要件
(注)調査結果は日本の登録特許だけを出力してください。
•ランニングシューズであること
•ミッドソールにプレートが配置されていること(ミッドソールの内部又は外面に配置)
•プレート材料は不問
•プレートの少なくとも一部が長手方向に湾曲していること
•ミッドソールの厚さは限定しない(“厚底”でなくても可)
[(URL)
MAGIC SPEED 4](https://www.asics.com/jp/ja-jp/mk/running/magicspeed?msockid=353f9dedf6d66faa3067883af7616e4f)|https://www.asics.com/jp/ja-jp/mk/running/magicspeed?msockid=353f9dedf6d66faa3067883af7616e4f結果は正解1件でした。知財情報フェアでも、生成AIと人間ともに正解が1件でしたので互角という結果でした。
結果を見るとミズノの案件が多数を占めていたのですが、人間側で参加した野崎さんと母集団が似ていると感じました。ミズノはミズノウェーブという技術を持っていて、それが多数引っかかったと思われます。
出題者としては、厚底シューズに使われるカーボンファイバープレートを意図していたので、関連の出願を多数行っているナイキが母集団に含まれていないとズレが大きいと思います。
Perplexity Patentsの結果には、ナイキの特許が1件も出力されていなかったので、出題者の意図とは違っている印象でした。
Perplexity Patentsで「生成AI vs 人間」の問題を解いてみた 続きを読む »
AWSの記事に「知財AIエージェント」を開発したという事例が紹介されています。注目すべきはその「実装の深さ」と「内製へのこだわり」です。
この知財AIエージェントは、特許庁のXML生データから独自の特許検索データベースを構築し、それを生成AIシステムと連携させています。これは、単にAPIを利用したり、プロンプトを作成したりする段階を大きく超えた、本格的なシステム開発です。
最大の戦略的ポイントは「内製化」
この複雑なシステムを外注に頼らず、内製することによる最大の利点は、システムの「ブラックボックス化」を排除できることにあります。内部処理がすべて把握できるため、なぜその結果を出したのかという「説明性」が格段に高まります。
知財業務において、判断の根拠やプロセスは極めて重要です。AIの回答を鵜呑みにするのではなく、そのプロセスを説明できることこそが、業務の品質と信頼性を担保します。
この事例は、AIを「使う」から「作る」フェーズへの移行を示しています。自社の業務プロセスに最適化し、かつ説明性を確保するため、今後このように高度なAIシステムを内製する企業は、ますます増えていくのではないでしょうか。
社内で新人技術者が統計検定2級を受けさせられているのを聞いても、私も受験して無事に合格することが出来ました。
合格証はこちら。
2級と聞くと簡単に思えるかもしれませんが、公式HPには「大学の教養課程レベル」と書かれています。
検定種別一覧
数検2級が「高校2年レベル」となっていますので、統計検定2級の方が難しめに設定されていることが分かります。
最近の学校教育の数学では「データ分析」を教わります。中学校からデータ分析を教わり、高校レベルになると推定・検定も習います。現在の数学の教育を受けている人であれば、高校数学にプラスαするだけで合格出来ると思います。
しかし、「データ分析」を大学までに習っていない(下手すると大学でもまともに学んでいない)人にとっては、かなり難しい試験だと思います。
統計検定2級に合格することで、「統計学」の専門書がかなり読めるようになりました。また、知財分野のデータ分析が危うい分析をしていることも分かるようになりました。
現在は、統計検定準1級に向けて勉強中です。準一級は数学的にさらに高度な内容になり、とても楽しく学んでいます。
Googleの勢いが止まらない。Bardと呼んでいたころの生成AIは使えなくて、ChatGPTの独壇場かと思われたが、Geminiの登場でついに逆転しそうな勢いになってきた。これはGoogleが「サイエンスの時代」に向け、着実に力を蓄えていた証拠なのだろう。
この背景には、流行に乗るだけでは到達できない領域を見据えたGoogleの姿勢がある。あらゆる産業は高度化すると、その進歩は必然的に表面的な改善から、原理原則に基づく科学的なアプローチへと収斂していく。Googleもこれに則って「サイエンス」としてAI基礎研究へ深く投資し続けてきたのだろう。
多くの生成AIモデルの基礎となっているTransformer技術についても、Googleは特許権を独占的に権利行使する道を選ばず、技術力で真っ向から勝負したと考えられる。このオープンな戦略が、結果としてAI分野全体の発展を促し、Google自身の技術革新へと繋がったと言える。
テクノロジーカンパニーにおいては、優れた技術があってこその知財であり、知財だけで技術が伴わなければ真の進歩は望めないのではないだろうか。